You shouldn't need a credit card
to call an LLM.
One OpenAI-compatible endpoint. Eight free LLM providers. One rate-limits, the next one answers. Stack 3 keys per provider and hit ~450 free requests per minute. All $0.
Everything you need to run LLMs for free
Routing, failover, caching, and observability built around the constraints of free-tier providers. Every feature solves a real free-tier problem.
Drop-in OpenAI SDK
Change one line. Your base URL. Your existing OpenAI SDK code keeps working against eight providers.
Automatic failover
Groq rate-limited? Your request silently routes to Gemini, then Mistral, then Cerebras. You stop seeing 429s.
Multi-key rotation
Set GROQ_API_KEY=k1,k2,k3 and stack multiple keys per provider. Each key gets its own rate-limit budget.
Token tracking
Rolling 24-hour token counts per provider. Always know how much of your free budget is left.
Circuit breakers
Per-provider health tracking with three states. Failures stay contained, recovery is automatic.
Three meta-models
Pick a strategy, not a provider. free-fast for speed, free-smart for reasoning, free for max uptime.
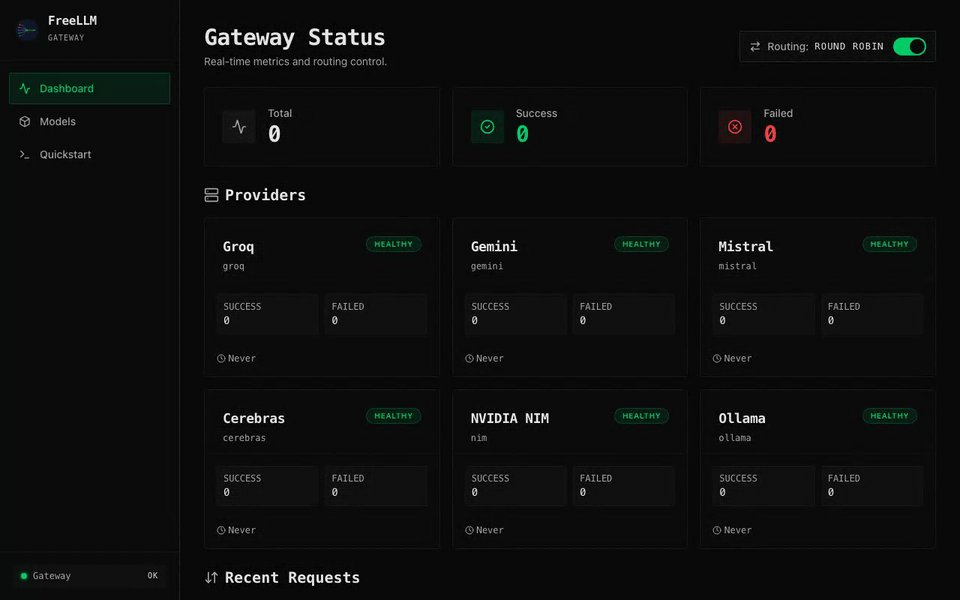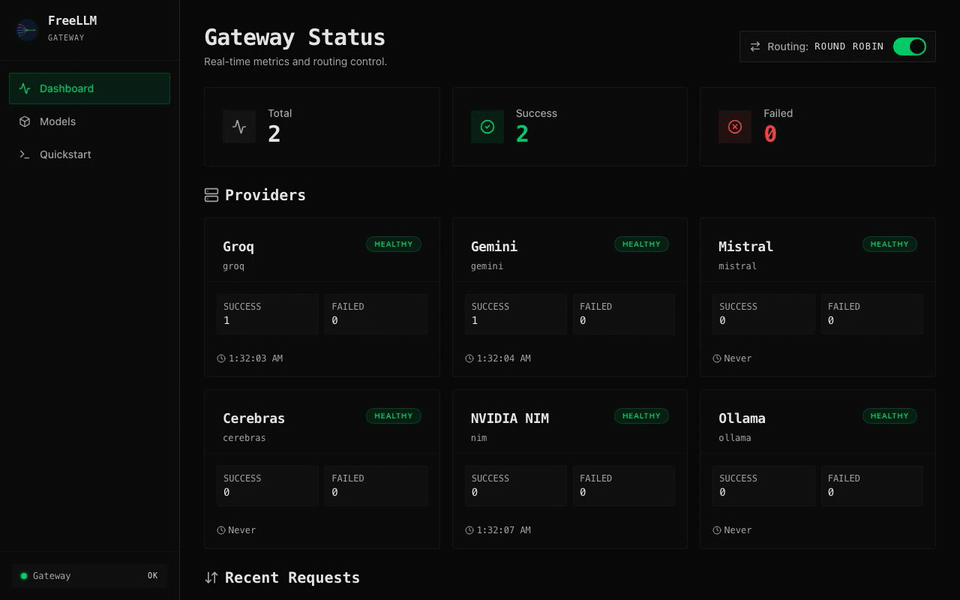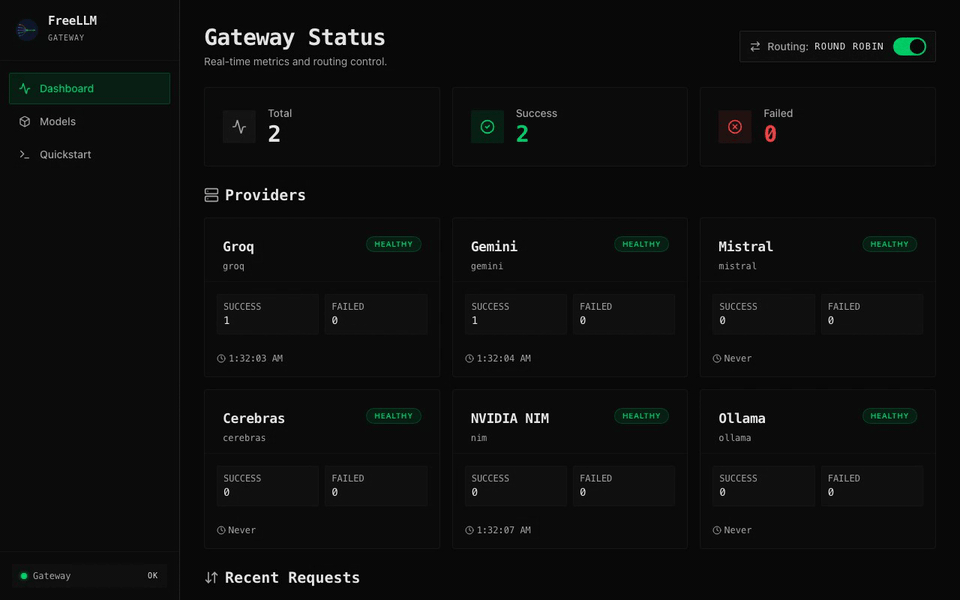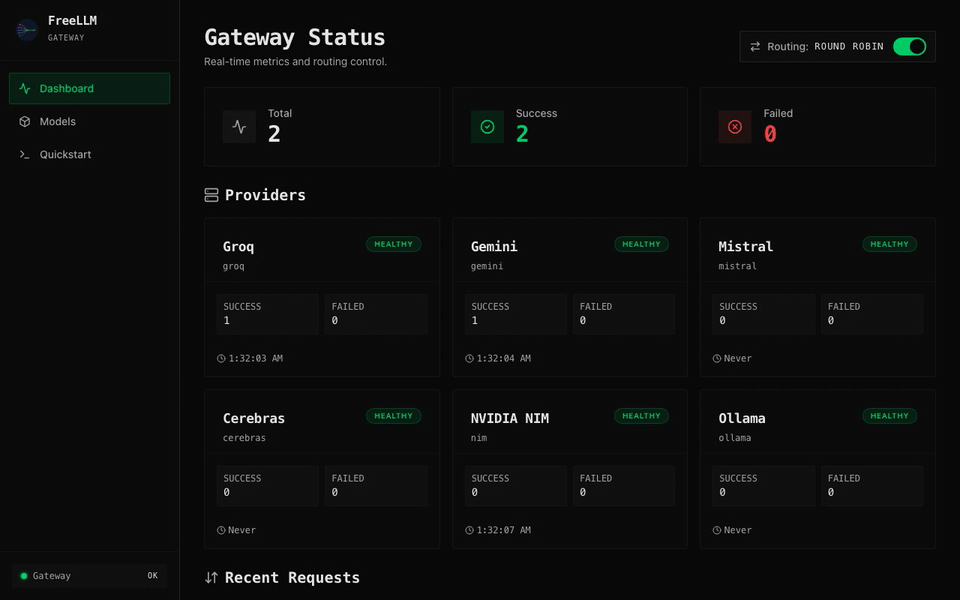
Real-time dashboard
Built-in dashboard shows provider health, live request log, latency, and token usage at a glance.
Truly $0
Every provider runs on its free tier. No markup, no subscription, no surprise bills. Self-host in 2 minutes.
Response caching
Identical prompts return in ~23ms with zero provider quota burn. 9× faster than the cold path. SHA-256 keyed, LRU eviction, configurable TTL.
Stitched into one endpoint
Sign up for whichever providers you want. Paste the keys into one .env file. FreeLLM handles the routing, the rate limits, and the failover.
Groq
~30 req/min per key
Llama 3.3 70B, Llama 3.1 8B, Llama 4 Scout, Qwen3 32B
Gemini
~15 req/min per key
Gemini 2.5 Flash, 2.5 Pro, 2.0 Flash, 2.0 Flash Lite
Mistral
~5 req/min per key
Mistral Small, Medium, Nemo
Cerebras
~30 req/min per key
Llama 3.1 8B, Qwen3 235B, GPT-OSS 120B
NVIDIA NIM
~40 req/min per key
Llama 3.3 70B, Llama 3.1 405B, Nemotron 70B, DeepSeek R1
GitHub Models
~15 req/min per key
GPT-4o-mini, Phi-4, Llama 3.3 70B, Mistral Large
Cloudflare AI
~10 req/min per key
Llama 3.3 70B, Llama 3.1 8B, Mistral 7B
Ollama
Unlimited (local)
Any local model on your hardware
With 3 keys per provider: ~450 req/min. All $0.
Change one line. Keep your code.
Any OpenAI-compatible SDK works. Swap your base URL. That's it.
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:3000/v1",
api_key="unused",
)
response = client.chat.completions.create(
model="free-fast",
messages=[{"role": "user", "content": "Hello!"}],
)
print(response.choices[0].message.content)
print("Provider used:", response.x_freellm_provider)import OpenAI from "openai";
const client = new OpenAI({
baseURL: "http://localhost:3000/v1",
apiKey: "unused",
});
const response = await client.chat.completions.create({
model: "free-smart",
messages: [{ role: "user", content: "Explain recursion." }],
});
console.log(response.choices[0].message.content);curl http://localhost:3000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "free",
"messages": [{"role": "user", "content": "Hello!"}]
}'The free-tier-first LLM gateway
Other gateways assume you pay per token. FreeLLM assumes you don't. That's why multi-key rotation and zero-markup pricing exist here and nowhere else.
| Feature | FreeLLM | LiteLLM | OpenRouter | Portkey |
|---|---|---|---|---|
| Truly $0 (no markup, no subscription) | ✓ | Self-host | — | — |
| Multi-key rotation per provider | ✓ | — | — | — |
| OpenAI-compatible | ✓ | ✓ | ✓ | ✓ |
| Automatic failover | ✓ | ✓ | ✓ | ✓ |
| Built-in real-time dashboard | ✓ | — | ✓ | ✓ |
| Response caching (zero quota burn) | ✓ | Plugin | — | ✓ |
| Per-provider token tracking | ✓ | ✓ | ✓ | ✓ |
| Circuit breakers | ✓ | Partial | ✓ | ✓ |
| Self-hosted | ✓ | ✓ | — | Both |
| TypeScript codebase (auditable) | ✓ | — | ? | — |
| One-click cloud deploy | ✓ | — | n/a | — |
Worst case: you delete it.
Two minutes to deploy, $0 to run. The decision takes longer than the setup.

