Token Usage Tracking
Free tiers don’t just have RPM limits. They have daily token caps (Groq: 500K/day, Gemini: 1M/day, etc.). FreeLLM tracks every successful request’s prompt_tokens and completion_tokens against a rolling 24-hour window per provider, so you always know how much of your free budget is left.
How it works
Every successful non-streaming response from an OpenAI-compatible provider includes a usage object:
{ "usage": { "prompt_tokens": 15, "completion_tokens": 42, "total_tokens": 57 }}FreeLLM extracts this and records it against the provider via the UsageTracker class, which uses hourly buckets (24 max per provider) for O(1) writes and O(24) reads. Memory footprint is tiny. Under 600 bytes per provider even when fully populated.
The data is in-memory and resets on process restart. This is acceptable because upstream providers reset their daily quotas independently. FreeLLM’s view will catch up within an hour as new requests come in.
API access
GET /v1/status exposes per-provider and gateway-wide totals:
{ "totalRequests": 87, "successRequests": 85, "failedRequests": 2, "usage": { "promptTokens": 142560, "completionTokens": 38912, "totalTokens": 181472, "requestCount": 85 }, "providers": [ { "id": "groq", "usage": { "promptTokens": 78000, "completionTokens": 19200, "totalTokens": 97200, "requestCount": 42 } } ]}Dashboard surfaces
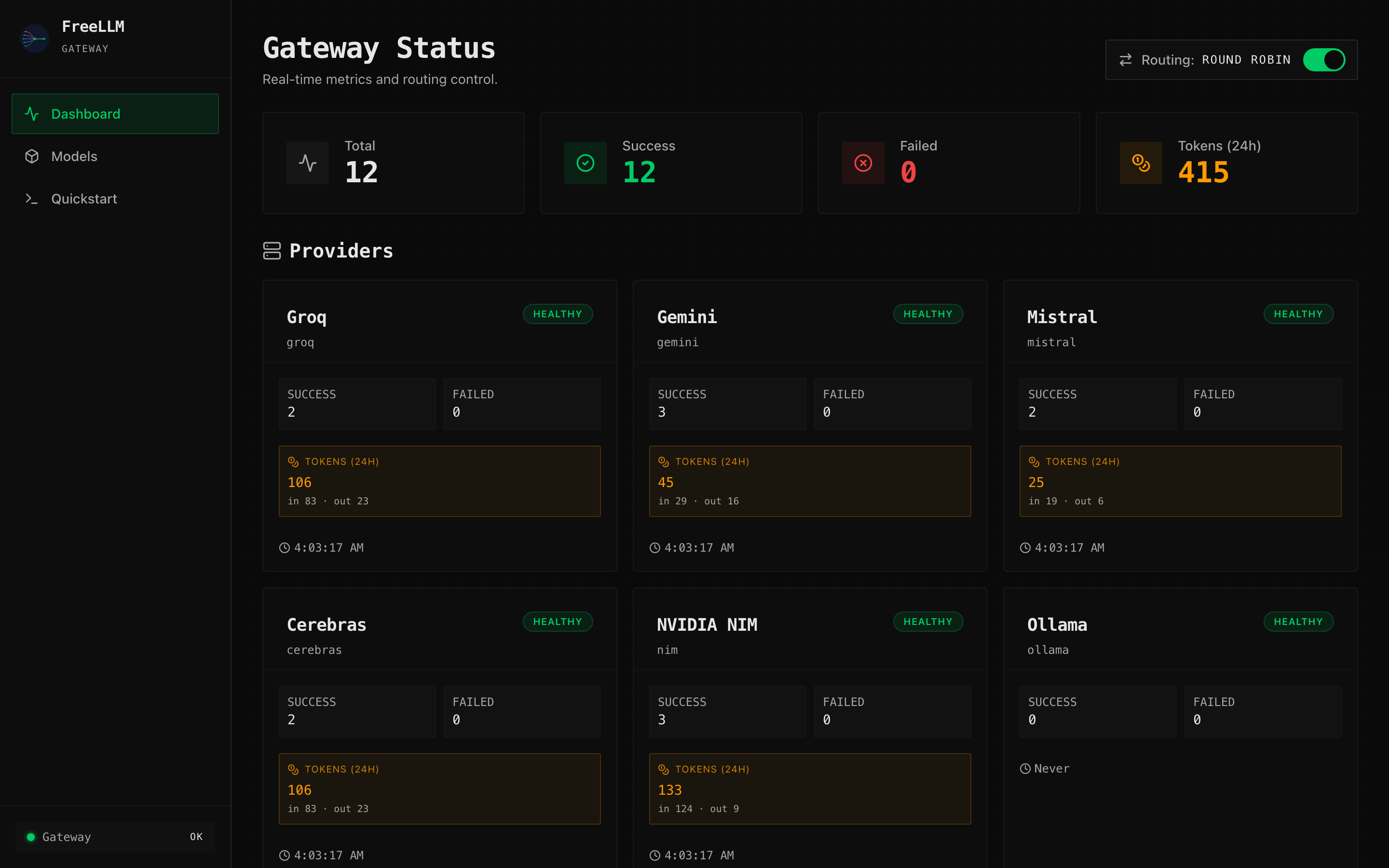
The dashboard shows token usage in three places:
- Top metrics row. Gateway-wide “Tokens (24h)” card with compact formatting (
1234 → "1.2K",1.5M → "1.50M"). - Provider cards. Per-provider amber “TOKENS (24H)” block showing total +
in X · out Ybreakdown. - Recent requests table. “Tokens” column showing
prompt → completionper request.
Streaming limitation
Streaming responses currently don’t track tokens. The OpenAI SSE protocol only includes a final usage chunk when the client passes stream_options: { include_usage: true }. FreeLLM doesn’t inject that flag automatically because we want to forward your request unchanged.
This will be addressed in a future release, either by:
- Auto-injecting
stream_options.include_usagewhenstream: true - Using a tokenizer (tiktoken or similar) to count tokens client-side