Introduction
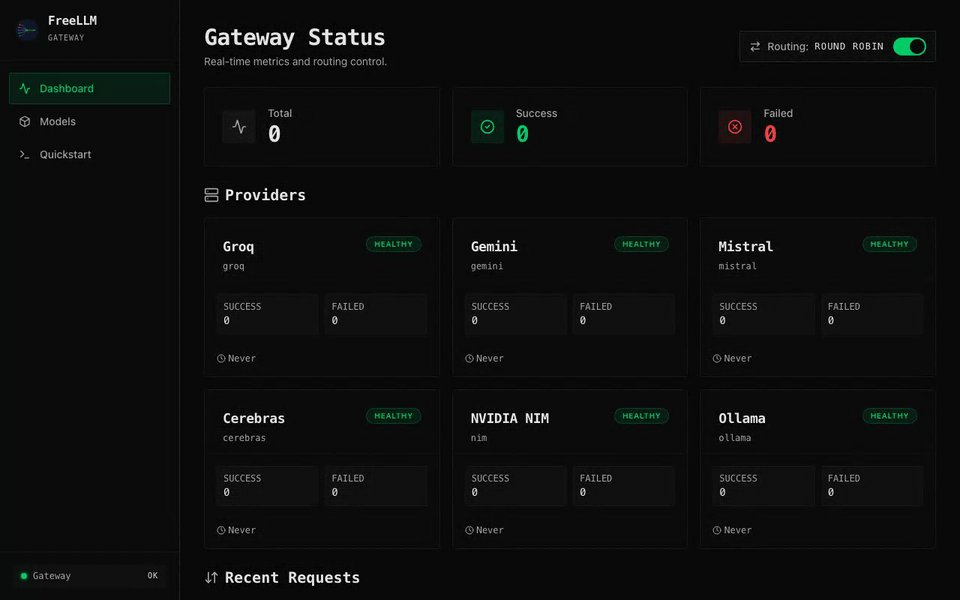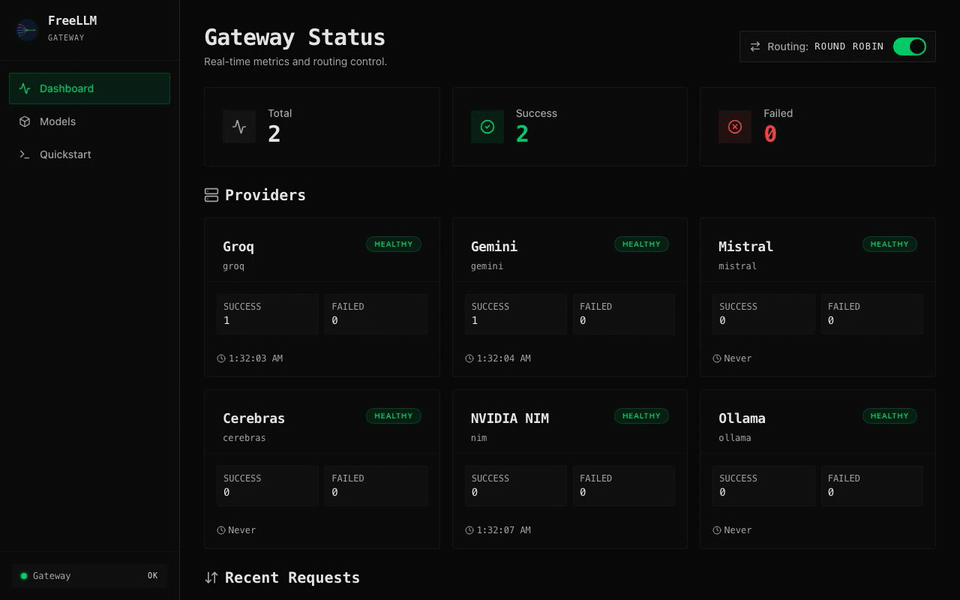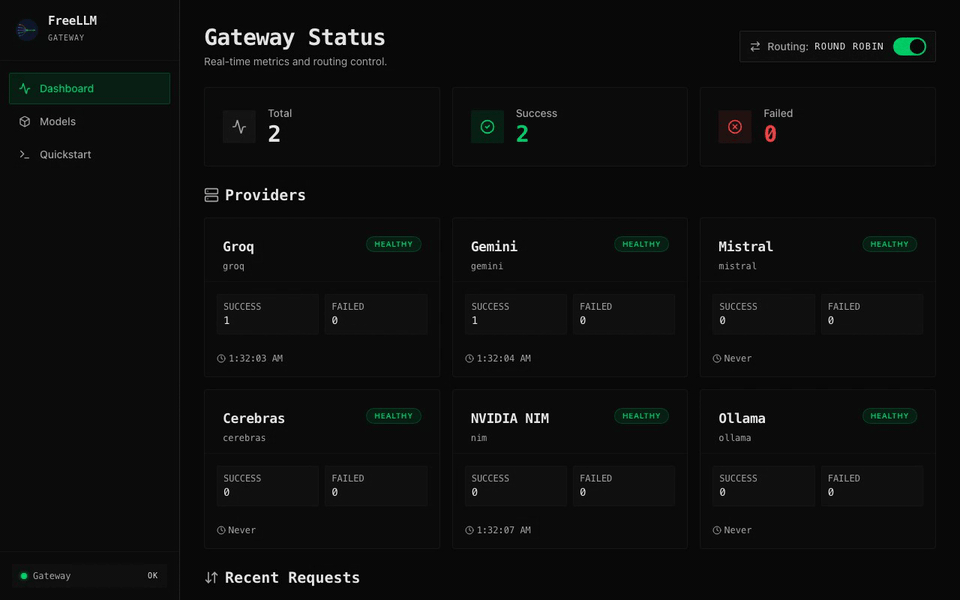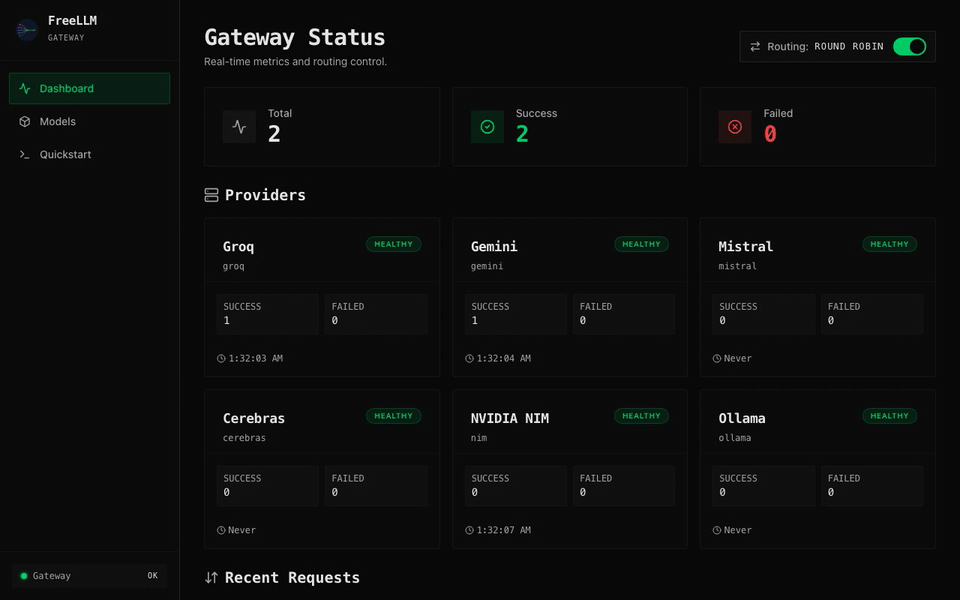
FreeLLM is an OpenAI-compatible gateway that stitches 6 free LLM providers (Groq, Gemini, Mistral, Cerebras, NVIDIA NIM, and Ollama) into a single endpoint. Automatic failover, multi-key rotation, response caching, and a real-time dashboard. Zero dollars.
Why this exists
Every major provider has a free tier. Groq, Gemini, Mistral, Cerebras, NVIDIA. All of them.
But using them is painful. Each one ships its own SDK. Each one has its own rate limits. Each one goes down at the worst possible time. So you end up writing provider-switching logic, handling 429s, and babysitting API keys across five different dashboards.
I built FreeLLM because I was tired of paying OpenAI $20 to test a prompt I’d run 30 times in an afternoon.
One line replaces all of that:
client = OpenAI(base_url="http://localhost:3000/v1", api_key="unused")That’s the entire migration.
What you get
- Drop-in OpenAI SDK. Swap your base URL. Keep your code.
- Automatic failover. Groq rate-limited? Routes to Gemini, then Mistral, then Cerebras.
- Multi-key rotation. Stack
GROQ_API_KEY=k1,k2,k3to triple your free capacity. - Response caching. Identical prompts return in ~23ms with zero quota burn. 9× faster than the cold path.
- Token tracking. Rolling 24h token counts per provider, so you always know how much of your free budget is left.
- Three meta-models.
free-fastfor speed,free-smartfor reasoning,freefor max uptime. - Real-time dashboard. Provider health, live request log, latency, token usage, cache hit rate.
- Circuit breakers. Failing providers get sidelined and tested for recovery automatically.
- Truly $0. No markup. No subscription. No surprise bills.
Where to go next
- Quickstart: deploy your gateway in 2 minutes
- Multi-key rotation: the killer feature, stack free tiers
- Response caching: duplicate prompts return in 23ms with zero quota burn
- Token usage tracking: never lose track of your free budget
- API reference: every endpoint, fully documented
- Comparison: how FreeLLM stacks against LiteLLM, OpenRouter, and Portkey